Extensions
一般信息
扩展是一种更方便的用户脚本形式。
扩展都存在于webui的扩展文件夹中自己的文件夹中。您可以使用git安装像这样的扩展:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients extensions/aesthetic-gradients
这将从https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients的扩展安装到扩展/aesthetic-gradients目录中。
或者,您可以将目录复制粘贴到扩展中。
有关开发扩展,请参阅开发扩展。
安全
由于扩展允许用户安装和运行任意代码,这可能会被恶意使用,并且在使用允许远程用户连接到服务器的选项运行时默认禁用(--share或--listen)-您仍然有用户界面,但尝试安装任何内容将导致错误。如果您想使用这些选项并且仍然能够安装扩展,请使用--enable-insecure-extension-access命令行标志。
扩展
带有平铺 VAE 的多重扩散
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
多重扩散
- txt2img全景生成,如MultiDiffusion中所述。
- 它可以与ControlNet合作,生成具有控制的宽图像。
全景示例:(链接截至2023年6月不起作用)之前:单击原始图像之后:单击原始图像
ControlNet Canny输出:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111/raw/docs/imgs/yourname.jpeg?原始=真实
平铺 VAE
vae_optimize.py脚本将图像拆分为图块,分别对每个图块进行编码,并合并结果。这个过程允许VAE以有限的VRAM(8K图像为~10 GB)生成大图像。
使用此脚本可能会允许删除--lowvram或--medvram参数,从而缩短图像生成时间。
VRAM估算器
https://github.com/space-nuko/a1111-stable-diffusion-webui-vram-estimator
在不断增加的尺寸和批处理大小的情况下运行txt2img、img2img、highres-fix,直到OOM,并将数据输出到图表中。

转储U-Net
https://github.com/hnmr293/stable-diffusion-webui-dumpunet
查看不同层,观察U-Net特征地图。通过为unet的每个块提供不同的提示来允许生成图像:https://note.com/kohya_ss/n/n93b7c01b0547

姿势
https://github.com/hnmr293/posex
Pose2Image的估计图像生成器。此扩展允许在3d空间中移动openpose图形。

LLuL
https://github.com/hnmr293/sd-webui-llul
本地潜在升级器。瞄准一个区域,有选择地增强细节。
cover_yuv420p.mp4
CFG-自动时间表1111-SD
https://github.com/guzuligo/CFG-Schedule-for-Automatic1111-SD
这2个脚本允许在生成步骤中进行动态CFG控制。使用正确的设置,这可以帮助获得高CFG的细节,而不会损坏生成的图像,即使img2img中的低去噪。
查看他们的维基,了解如何使用。
a1111-sd-webui-locon
https://github.com/KohakuBlueleaf/a1111-sd-webui-locon 在webui中加载LoCon网络的扩展。
ebsynth_实用性
https://github.com/s9roll7/ebsynth_utility
使用img2img和ebsynth创建视频的扩展。使用ebsynth输出编辑的视频。与ControlNet扩展一起使用。

LoRA块重量
LoRA是一个强大的工具,但它有时很难使用,并且可以影响您不希望它影响的区域。此脚本允许您逐块设置权重。使用此脚本,您或许能够获得您想要的图像。
与XY图一起使用,可以检查层次结构的每个级别的影响。

包含的预设:
NOT:0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
ALL:1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1
INS:1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0
IND:1,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0
INALL:1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0
MIDD:1,0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,0
OUTD:1,0,0,0,0,0,0,0,0,1,1,1,1,1,0,0,0,0
OUTS:1,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1
OUTALL:1,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1
厨房主题
https://github.com/canisminor1990/sd-web-ui-kitchen-theme
webui的自定义主题。

双语本地化
https://github.com/journey-ad/sd-webui-bilingual-localization
双语翻译,无需担心如何找到原始按钮。与语言包扩展兼容,无需重新导入。

可组合的LoRA
https://github.com/opparco/stable-diffusion-webui-composable-lora
允许使用AND关键字(可组合扩散)将LoRA限制为子提示。与潜在夫妇扩展配对时很有用。
剪辑审讯者
https://github.com/pharmapsychotic/clip-interrogator-ext
药代精神病药的Clip Interrogator移植到扩展。具有各种剪辑模型和询问设置。

潜在夫妇
https://github.com/opparco/stable-diffusion-webui-two-shot
内置可组合扩散的扩展,允许您确定反映子提示的潜在空间区域。

OpenPose编辑器
https://github.com/fkunn1326/openpose-editor
这可以添加多个姿势字符,从图像中检测姿势,保存到PNG,并发送到控制网扩展。

超级合并
https://github.com/hako-mikan/sd-webui-supermerger
合并并运行,无需保存以驱动。顺序XY合并世代;提取和合并LoRA,将LoRA绑定到ckpt,合并块权重等。

即时翻译
https://github.com/butaixianran/Stable-Diffusion-Webui-Prompt-Translator
使用Deepl或百度将提示翻译成英语的集成翻译器。

视频循环
https://github.com/fishslot/video_loopback_for_webui
视频_loopback_v2.mp4
矿井扩散
https://github.com/fropych/mine-diffusion
此扩展将图像转换为块,并创建原理图,以便使用Litematica mod轻松导入《我的世界》。
示例:

抗烧伤
https://github.com/klimaleksus/stable-diffusion-webui-anti-burn
通过跳过最后几个步骤并将它们之前的一些图像平均起来来平滑生成的图像。

嵌入合并
https://github.com/klimaleksus/stable-diffusion-webui-embedding-merge
在运行时从字符串文字合并文本反转嵌入。

gif2gif
此脚本的目的是接受动画GIF作为输入,像img2img通常那样处理帧,并将它们重新组合成动画GIF。旨在提供有趣、快速的gif到gif工作流程,支持新的模型和方法,如Controlnet和InstructPix2Pix。放一个动图,然后走。来自promts_from_file的引用代码。
示例:

咖啡馆美学
https://github.com/p1atdev/stable-diffusion-webui-cafe-aesthetic
预先训练的模型,确定是否审美/非审美,做5种不同的风格识别模式,以及Waifu确认。还有一个带有批量处理的选项卡。

Catppuccin主题
https://github.com/catppuccin/stable-diffusion-webui
Catppuccin是一个社区驱动的粉彩主题,旨在成为低对比度和高对比度主题之间的中间地带。添加一组符合catppucin指南的主题。

动态阈值
动态阈值增加了可定制的动态阈值,允许高CFG比例值,而不会产生燃烧/“流行艺术”效果。
自定义扩散
https://github.com/guaneec/custom-diffusion-webui
自定义扩散是一种使用TI进行微调的形式,而不是对整个模型进行微调。与TI相似的速度和内存要求,并且可能以更少的步骤获得更好的结果。
融合
https://github.com/ljleb/prompt-fusion-extension
添加提示旅行和类似移位注意力的插值(见exts),但在采样步骤期间/内。Always-on +适用于现有的提示编辑语法。各种插值模式。有关更多信息,请参阅他们的维基。
示例:

像素化
https://github.com/AUTOMATIC1111/stable-diffusion-webui-pixelization
使用预先训练的模型,在额外选项卡中用图像生成像素艺术。

指示-pix2pix
https://github.com/Klace/stable-diffusion-webui-instruct-pix2pix
添加一个用于使用 instruct-pix2pix 模型进行 img2img 编辑的选项卡。作者将该功能添加到webui中,因此无需使用。
系统信息
https://github.com/vladmandic/sd-extension-system-info
在自动WebUI中创建一个顶级系统信息选项卡
笔记:
- 如果选项卡可见,状态和内存信息每秒自动更新
(当选项卡不可见时,不会执行更新) - 所有其他信息在WebUI加载后立即更新,并且
如果需要,可以强制刷新
步骤动画
https://github.com/vladmandic/sd-extension-steps-animation
从去噪的中间步骤创建动画序列的扩展
在txt2img和img2img选项卡中注册脚本
创建动画对整体性能的影响最小,因为它不需要单独运行
除了增加将每个中间步骤保存为图像的开销,外加几秒钟来实际创建电影文件
支持颜色和运动插值,从任意数量的临时步骤实现所需持续时间的动画
由于优化了编解码器设置,由此产生的电影场景通常非常小(平均约为1MB)
美学记分员
https://github.com/vladmandic/sd-extension-aesthetic-scorer
使用现有的CLiP模型和额外的小型预训练来计算图像的感知美学分数
通过Settings启用或禁用->Aesthetic scorer
这是一个“隐形”扩展,它在任何图像保存之前在后台运行
将score附加为PNG信息部分和/或EXIF注释字段
备注
- 通过设置进行配置→美学记分器
- 扩展服从现有的将VAE和CLiP移动到RAM设置
- 模型将在首次使用时自动下载(小)
- 分数值是
0..10 - 支持
CLiP-ViT-L/14和CLiP-ViT-B/16 - 跨平台!
不和谐丰富的存在
https://github.com/kabachuha/discord-rpc-for-automatic1111-webui
提供与Discord RPC的连接,在用户配置文件中显示一个花哨的表格。
Promptgen
https://github.com/AUTOMATIC1111/stable-diffusion-webui-promptgen
使用变压器模型生成提示。

haku-img
https://github.com/KohakuBlueleaf/a1111-sd-webui-haku-img
图像实用程序扩展。允许混合、分层、色调和颜色调整、模糊和素描效果以及基本像素化。

合并块加权
https://github.com/bbc-mc/sdweb-merge-block-weighted-gui
为每个25个U-Net块(输入、中间、输出)以单独的速率合并模型。

稳定的部落工人
https://github.com/sdwebui-w-horde/sd-webui-stable-horde-worker
非官方的稳定部落工人桥作为Stable Diffusion WebUI扩展。
精选
此扩展仍在进行中,尚未准备好投入生产使用。
- 从稳定部落获得工作,生成图像并提交几代人
- 每项工作之间的可配置间隔
- 随时启用和禁用扩展
- 检测当前模型并实时获取相应的作业
- 在Stable Diffusion WebUI中显示生成图像
- 将带有png信息文本的生成图像保存到本地
安装
-
在Stable Diffusion WebUI安装的根目录中运行以下命令:
shell git clone https://github.com/sdwebui-w-horde/sd-webui-stable-horde-worker.git extensions/stable-horde-worker -
启动Stable Diffusion WebUI,您将看到
Stable Horde Worker选项卡页面。
-
Register an account on Stable Horde and get your
API keyif you don't have one.注意:默认的匿名密钥
00000000对工人不起作用,您需要注册一个帐户并获得自己的密钥。 -
在这里设置您的
API key。 -
在这里设置带有专有名称的
Worker name。 -
确保已选中
Enable。 -
单击
Apply settings按钮。
稳定的部落
稳定的部落客户
https://github.com/natanjunges/stable-diffusion-webui-stable-horde
Generate pictures using other user's PC. You should be able to receive images from the stable horde with anonymous 0000000000 api key, however it is recommended to get your own - https://stablehorde.net/register
注意:检索图像可能需要2分钟或更长时间,特别是如果您没有荣誉。
多个超网络
https://github.com/antis0007/sd-webui-multiple-hypernetworks
允许同时使用多个超网络的扩展

超网络-猴子补丁-扩展
https://github.com/aria1th/Hypernetwork-MonkeyPatch-Extension
扩展为超网络培训提供额外的培训功能,并支持多个超网络。

终极SD升级器
https://github.com/Coyote-A/ultimate-upscale-for-automatic1111

SD Upscale的更高级选项,使用更高的去噪比(0.3-0.5)的工件比原件少。
模型转换器
https://github.com/Akegarasu/sd-webui-model-converter
模型转换扩展,支持转换fp16/bf16 no-ema/仅ema的安全张力。
Kohya-ss附加网络
https://github.com/kohya-ss/sd-webui-additional-networks
允许Web UI使用由其脚本训练的网络(LoRA)来生成图像。编辑safetensors提示符和其他元数据,并使用2。X LoRAs。
将图像编号添加到网格中
https://github.com/AlUlkesh/sd_grid_add_image_number
将图像的编号添加到网格中的图片中。
快速css
https://github.com/Gerschel/sd-web-ui-quickcss
用于快速选择和应用custom.css文件的扩展,用于自定义ui中元素的外观和位置。


提示生成器
https://github.com/imrayya/stable-diffusion-webui-Prompt_Generator
在webui中添加一个选项卡,允许用户从小基础提示符生成提示。基于FredZhang7/distilgpt2-stable-diffusion-v2。

模型关键词
https://github.com/mix1009/model-keyword
自动将匹配的关键字插入到提示符中。更新扩展以获取最新的模型+关键字映射。

sd-模型预览
https://github.com/Vetchems/sd-model-preview
允许您创建与模型同名的txt文件和jpg/png,并轻松显示此信息,以便以后在webui中参考。

增强型img2img
https://github.com/OedoSoldier/enhanced-img2img
一个支持分批和更好的涂漆的扩展。有关更多详细信息,请参阅readme。

openOutpaint扩展
https://github.com/zero01101/openOutpaint-webUI-extension
带有完整openOutpaint UI的选项卡。使用--api标志运行。

保存中间图像
https://github.com/AlUlkesh/sd_save_intermediate_images
实现保存中间图像,具有更高级的功能。



流变
https://github.com/enlyth/sd-webui-riffusion
使用Riffusion模型在gradio中制作音乐。要复制原始插值技术,请将提示旅行扩展输出帧输入到riffusion选项卡中。


DH补丁
https://github.com/d8ahazard/sd_auto_fix
D8ahazard的随机补丁。v2,2.1型号的自动加载配置YAML文件;修补潜在扩散,以固定对2.1型号(没有一半的黑匣子)的关注,无论我还想出什么。
预设实用程序
https://github.com/Gerschel/sd_web_ui_preset_utils
UI的预设工具。支持一些自定义脚本的预设。

配置预设
https://github.com/Zyin055/Config-Presets
添加一个可配置的下拉菜单,允许您更改txt2img和img2img选项卡中的UI预设设置。

扩散防御者
https://github.com/WildBanjos/DiffusionDefender
提示黑名单,查找和替换,用于半私人和公共实例。
NSFW检查器
https://github.com/AUTOMATIC1111/stable-diffusion-webui-nsfw-censor
将NSFW图像替换为黑色。
无限网格生成器
https://github.com/mcmonkeyprojects/sd-infinity-grid-generator-script
使用您选择的参数构建一个yaml文件,并生成无限维网格。内置向字段添加描述文本的能力。有关使用详情,请参阅readme。

嵌入检查器
https://github.com/tkalayci71/embedding-inspector
检查任何令牌(一个单词)或文本反转嵌入,并找出哪些嵌入是相似的。您可以在几秒钟内混合、修改或创建嵌入。此后,发布了更多有趣的选项,请参阅此处。

提示画廊
https://github.com/dr413677671/PromptGallery-stable-diffusion-webui
构建一个充满角色提示的yaml文件,点击生成,并通过他们的单词属性和修饰符快速预览它们。

DAAM
https://github.com/toriato/stable-diffusion-webui-daam
DAAM代表扩散注意力归因地图。输入注意文本(必须是提示中包含的字符串)并运行。将与原始图像一起生成一个带有每个注意力的热图的重叠图像。

可视化交叉注意力
https://github.com/benkyoujouzu/stable-diffusion-webui-visualize-cross-attention-extension
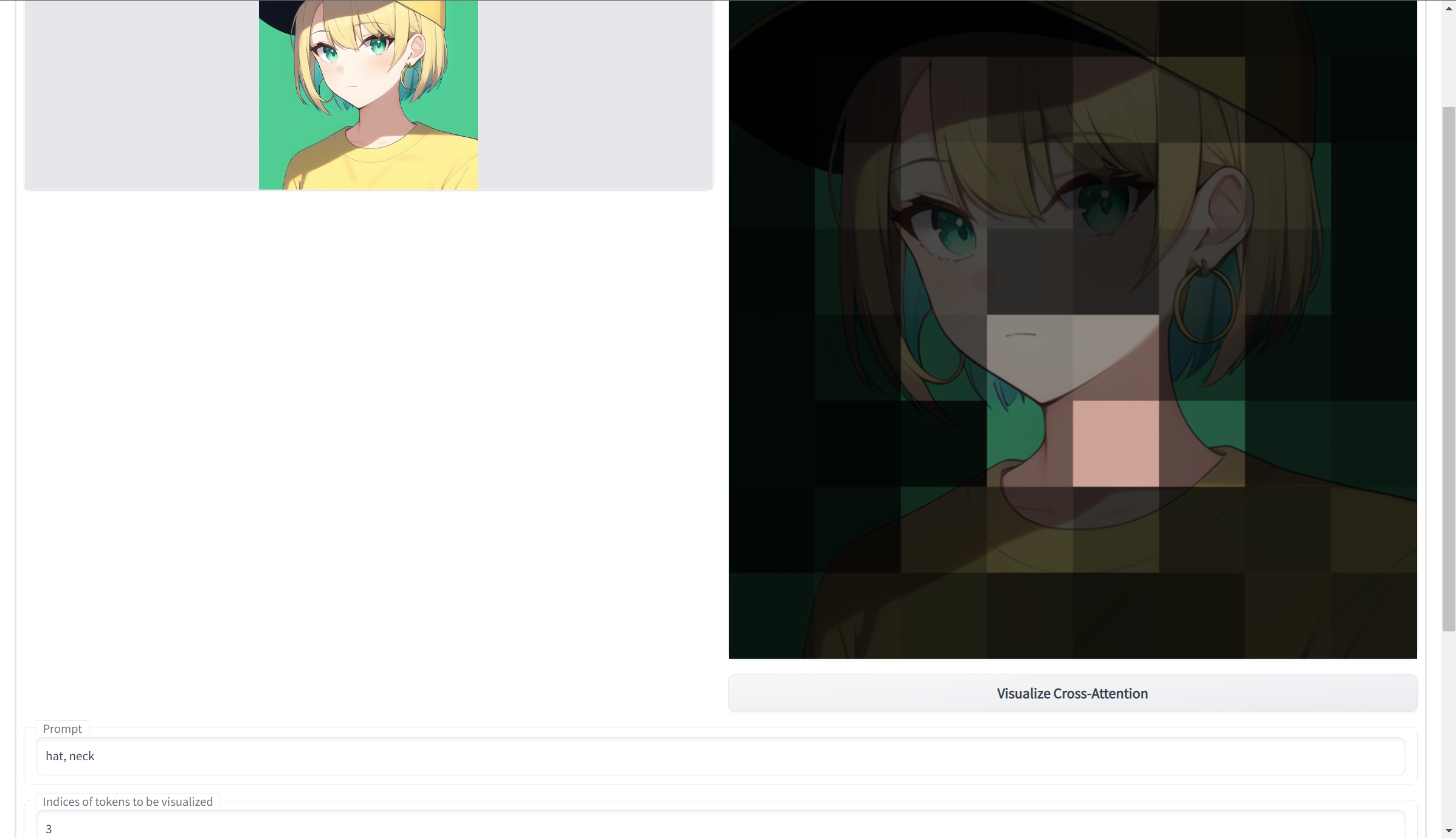
根据输入提示,生成已提交的输入图像的突出显示扇区。与令牌器扩展一起使用。有关更多信息,请参阅readme。
ABG_扩展
https://github.com/KutsuyaYuki/ABG_extension
自动删除背景。使用对动漫图像进行微调的onnx模型。在GPU上运行。
 |
 |
 |
 |
|---|---|---|---|
 |
 |
 |
 |
深度图2掩码
https://github.com/Extraltodeus/depthmap2mask
根据MiDaS的深度估计为img2img创建掩码。



多主题渲染
https://github.com/Extraltodeus/multi-subject-render
这是一个深度感知扩展,可以帮助在单个图像上创建多个复杂的主题。它生成一个背景,然后是多个前景主题,在深度分析后剪切背景,将它们粘贴到背景上,最后进行img2img以完成。

深度地图
https://github.com/thygate/stable-diffusion-webui-depthmap-script
从生成的图像创建深度图。结果可以在3D或全息设备上查看,如VR耳机或镜子显示器,用于带有位移修饰符的飞机上的渲染或游戏引擎,甚至可能3D打印。

合并委员会
https://github.com/bbc-mc/sdweb-merge-board
多车道合并支持(最多10条)。将您的合并组合保存并加载为食谱,这是简单的文本。

另见:
https://github.com/Maurdekye/model-kitchen
gelbooru-提示
https://github.com/antis0007/sd-webui-gelbooru-prompt
使用图像的散列获取标签。
booru2prompt
https://github.com/Malisius/booru2prompt
此SD扩展允许您将各种图像boorus的帖子转换为稳定的扩散提示。它通过从他们的API中提取标签列表来做到这一点。您可以复制粘贴到您想要的帖子的链接中,或者使用内置的搜索功能来完成这一切,而无需离开SD。

另见:
https://github.com/stysmmaker/stable-diffusion-webui-booru-prompt
WD 1.4 Tagger
https://github.com/toriato/stable-diffusion-webui-wd14-tagger
使用经过训练的模型文件,生成WD 1.4标签。模型链接 - https://mega.nz/file/ptA2jSSB#G4INKHQG2x2pGAVQBn-yd_U5dMgevGF8YYM9CR_R1SY

梦想艺术家
https://github.com/7eu7d7/DreamArtist-sd-webui-extension
通过对比提示调整实现可控的一次性文本到图像生成。

自动TLS-HTTPS
https://github.com/papuSpartan/stable-diffusion-webui-auto-tls-https
允许您轻松,甚至完全自动开始使用HTTPS。
随机化
~https://github.com/stysmmaker/stable-diffusion-webui-randomize~ fork:https://github.com/innightwolfsleep/stable-diffusion-webui-randomize
允许在txt2img生成期间使用随机参数。此脚本适用于所有世代,无论选择哪种脚本,这意味着此脚本也将与其他脚本一起运行,例如AUTOMATIC1111/stable-diffusion-webui-wildcards。
调节-高分辨率修复
https://github.com/klimaleksus/stable-diffusion-webui-conditioning-highres-fix
这是重写Inpainting调理面罩强度值相对于运行时去噪强度的扩展。这对于Inpainting模型很有用,如sd-v1-5-inpainting.ckpt

检测细节
https://github.com/dustysys/ddetailer
Stable Diffusion Web UI的对象检测和自动屏蔽扩展。

声纳
https://github.com/Kahsolt/stable-diffusion-webui-sonar
提高生成的图像质量,搜索类似的(甚至更好!)一些已知图像附近的图像,专注于单个提示优化,而不是在多个提示之间移动。


快速旅行
https://github.com/Kahsolt/stable-diffusion-webui-prompt-travel
AUTOMATIC1111/stable-diffusion-webui的扩展脚本在潜在空间的提示之间移动。
示例:

转移注意力
https://github.com/yownas/shift-attention
在提示符中生成一系列转移注意力的图像。此脚本使您能够在提示中为令牌的重量提供一个范围,然后生成从第一个到第二个的图像序列。
移位-00003.mp4
种子旅行
https://github.com/yownas/seed_travel
AUTOMATIC1111/stable-diffusion-webui的小脚本,用于创建存在于种子之间的图像。
示例:

嵌入编辑器
https://github.com/CodeExplode/stable-diffusion-webui-embedding-editor
允许您使用滑块手动编辑文本反转嵌入。

潜在镜像
https://github.com/dfaker/SD-latent-mirroring
将镜像和翻转应用于潜在图像,以产生从微妙的平衡构图到完美反射的任何东西

风格堆
https://github.com/some9000/StylePile
将元素与影响结果样式的提示进行混合和匹配的简单方法。

推到拥抱
https://github.com/camenduru/stable-diffusion-webui-huggingface

要安装它,请将repo克隆到extensions目录中,然后重新启动web ui:
git clone https://github.com/camenduru/stable-diffusion-webui-huggingface
pip install huggingface-hub
代币化器
https://github.com/AUTOMATIC1111/stable-diffusion-webui-tokenizer
添加一个选项卡,允许您预览CLIP模型如何标记您的文本。

novelai-2-local-prompt
https://github.com/animerl/novelai-2-local-prompt
添加一个按钮来转换Novelifor中使用的提示,以用于WebUI。此外,添加一个按钮,允许您调用之前使用的提示。

Booru标签自动完成
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
显示Danbooru等“image booru”板标签的自动完成提示。使用本地标签CSV文件,并包含自定义配置。

未经提示
https://github.com/ThereforeGames/unprompted
用这种强大的脚本语言增强您的快速工作流程!

Unprompted是AUTOMATIC1111Stable Diffusion Web UI的高度模块化扩展,允许您在提示中包含各种短代码。您可以从文件中提取文本,设置自己的变量,通过条件函数处理文本等等-这就像类固醇上的通配符。
虽然预期的用例是Stable Diffusion ,但该引擎也足够灵活,可以作为多用途文本生成器。
训练挑选者
https://github.com/Maurdekye/training-picker
在webui中添加一个选项卡,允许用户自动从视频中提取关键帧,并手动提取这些帧的512x512作物,以用于模型训练。

安装
- 安装AUTOMATIC1111的Stable Diffusion Webui
- 为您的操作系统安装ffmpeg
- 将此存储库克隆到webui内的扩展文件夹中
- 将您想要提取裁剪帧的视频放入training-picker/videos文件夹中
自动-sd-油漆-ext
https://github.com/Interpause/auto-sd-paint-ext
使用Krita插件扩展AUTOMATIC1111的webUI(其他绘图工作室即将推出?)

- 优化的工作流程(txt2img、img2img、inpaint、upscale)和UI设计。
- 只有公开脚本API的绘图工作室插件。
有关计划开发,请参阅https://github.com/Interpause/auto-sd-paint-ext/issues/41。有关完整的更改日志,请参阅CHANGELOG.md。
数据集标签编辑器
https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
这是AUTOMATIC1111为Stable Diffusion Web UI的训练数据集中编辑字幕的扩展。
它与逗号分隔风格的文本字幕(例如DeepBooru interrogator生成的标签)配合得很好。
可以加载图像文件名中的标题,但编辑后的标题只能以文本文件的形式保存。

美学图像记分员
https://github.com/tsngo/stable-diffusion-webui-aesthetic-image-scorer
https://github.com/AUTOMATIC1111/stable-diffusion-webui的扩展
使用基于Chad Scorer的CLIP+MLP美学评分预测器计算生成图像的美学评分
查看讨论
使用计划的其他选项将分数保存到窗口标签中

要学习的艺术家
https://github.com/camenduru/stable-diffusion-webui-artists-to-study
https://artiststostudy.pages.dev/ 适用于网络ui的扩展。
要安装它,请将repo克隆到extensions目录中,然后重新启动web ui:
git clone https://github.com/camenduru/stable-diffusion-webui-artists-to-study
您可以通过单击将艺术家名称添加到剪贴板中。(感谢@gmaciocci的想法)

论坛
https://github.com/deforum-art/deforum-for-automatic1111-webui
Deforum的官方移植版,一个用于2D和3D动画的广泛脚本,支持密钥可帧序列、动态数学参数(甚至在提示内)、动态屏蔽、深度估计和翘曲。

灵感
https://github.com/yfszzx/stable-diffusion-webui-inspiration
随机显示艺术家或艺术流派典型风格的图片,选择后会显示该艺术家或流派的更多图片。因此,你不必担心在创作时选择正确的艺术风格有多难。

图像浏览器
https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
提供在Web浏览器中浏览已创建图像的界面,允许按EXIF数据进行排序和过滤。

智能流程
https://github.com/d8ahazard/sd_smartprocess
智能裁剪、字幕和图像增强。

梦亭
https://github.com/d8ahazard/sd_dreambooth_extension
用户界面中的Dreambooth。有关调优和配置要求,请参阅项目自述。包括LoRA(低级改编)
基于ShivamShiaro的回购协议。
动态提示
https://github.com/adieyal/sd-dynamic-prompts
AUTOMATIC1111/stable-diffusion-webui的自定义扩展,实现了用于随机或组合提示生成的富有表现力的模板语言,以及支持深度通配符目录结构的功能。
阅读更多功能和补充内容显示在自述中。

使用此扩展,提示:
A {house|apartment|lodge|cottage} in {summer|winter|autumn|spring} by {2$$artist1|artist2|artist3}
以下任何提示会提示吗:
- 艺术家1,艺术家2的夏天的房子
- 艺术家3,艺术家1的秋天小屋
- 艺术家2,艺术家3的冬季小屋
- ...
如果您正在寻找艺术家和风格的有趣组合,这尤其有用。
您还可以从文件中随机选择一个字符串。假设您在WILDCARD_DIR中有seasons.txt文件(见下文),那么:
__seasons__ is coming
可能会生成以下内容:
- 冬天来了
- 春天来了
- ...
您也可以使用相同的通配符两次
I love __seasons__ better than __seasons__
- 比起夏天,我更喜欢冬天
- 比起春天,我更喜欢春天
通配符
https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards
允许您在提示符中使用__name__语法,从通配符目录中名为name.txt的文件中获取一行随机。
美学梯度
https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients
从一张或几张图片中创建嵌入,并使用它来将其样式应用于生成的图像。

3D模型和Pose装载机
https://github.com/jtydhr88/sd-3dmodel-loader
一个自定义扩展,允许您在webui中加载本地3D模型/动画,或编辑姿势,然后将屏幕截图发送到txt2img或img2img作为ControlNet的参考图像。

画布编辑器
https://github.com/jtydhr88/sd-canvas-editor
sd-webui的自定义扩展,集成了全功能画布编辑器,您可以使用图层、文本、图像、元素等。

一个按钮提示
https://github.com/AIrjen/OneButtonPrompt
一个按钮提示是自动1111的工具/脚本,适用于在编写好提示时遇到问题的初学者或希望获得灵感的高级用户。
它从头开始生成整个提示。它是随机的,但被控制了。您只需加载脚本并按生成键,让它让您感到惊讶。
模型下载器
https://github.com/Iyashinouta/sd-model-downloader
SD-Webui扩展,从CivitAI和HuggingFace下载模型,推荐给云用户(又名Google Colab等)
SD电报
https://github.com/amputator84/sd_telegram
aiogram上的电报机器人在本地自动1111中生成图像(127.0.0.1:7860 nowebui)
如果您想通过电报机器人管理它,请通过扩展程序安装它。进一步的说明在github上。机器人使用sdwebuiapi并使用本地地址工作。
能够生成预览、全尺寸图片,还可以发送文档和组。能够“编写”提示,从词典中获取它们,所有模型都有一个流生成脚本。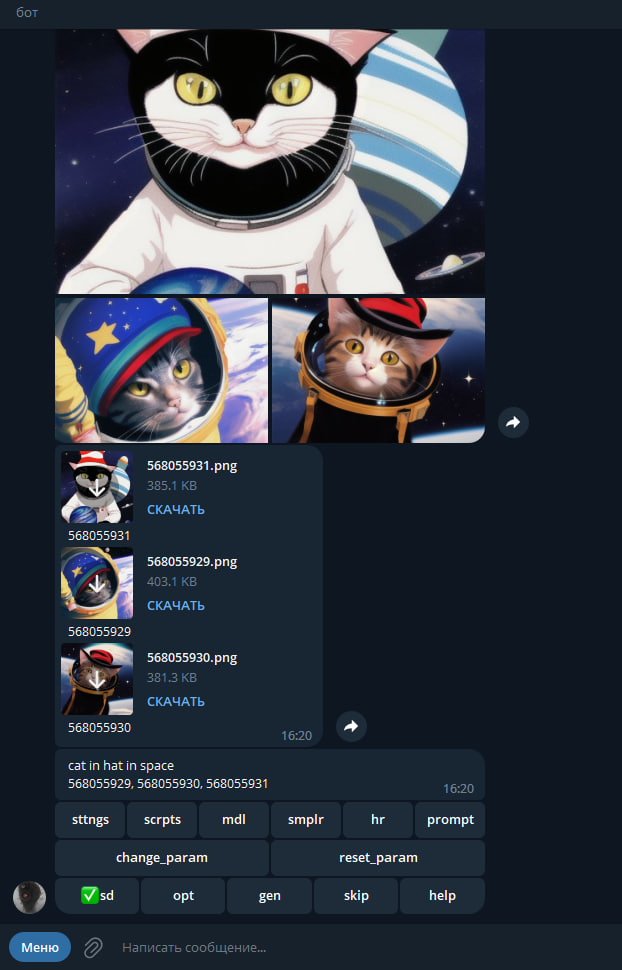
二维码生成器
https://github.com/missionfloyd/webui-qrcode-generator
立即为ControlNet生成二维码。

{kind=link}
{kind=link}
{kind=link}