Features
这是Stable Diffusion Web UI的功能展示页面。
除非另有说明,否则所有示例均非樱桃采摘。
SD-XL
下载
有两种型号可供选择。第一个是主要模型。
这些模型特别推荐用于生成、合并和训练。
他们有一个由madebyollin内置的训练有素的vae,可以修复在fp16中运行的NaN无穷计算。(这是最新的VAE供参考)
SD-XL BASE
这是一个专为生成质量1024×1024大小图像而设计的模型。它不是为了在512×512生成好图片。
经过测试,可以生成与Stability-AI的repo相同的(或非常接近的)图像(需要设置中的随机数生成器源= CPU)

- 文本反转 should not work, embeddings need to be created specifically for SDXL.
- train tab will not work.
- DDIM, PLMS, UniPC samplers do not work for SDXL
- --lowvram, --medvram works
- attention optimizations work
- SDXL Loras work
- works at minimum 4gb gpu (30XX)
SD-XL REFINER
This secondary model is designed to process the 1024×1024 SD-XL image near completion*, to further enhance and refine details in your final output picture. You could use it to refine finished pictures in the img2img tab as well.
- wcde/sd-webui-refiner *要尝试这种生成,您可以使用此扩展。
SD2 Variation Models
支持用于生成图像变化的Stable Diffusion -2-1-非剪辑检查点。
它的工作方式与当前对SD2.0深度模型的支持相同,即您从img2img选项卡运行它,它从输入图像中提取信息(在这种情况下,CLIP或OpenCLIP嵌入),并在文本提示符之外将这些信息输入到模型中。通常,您这样做时将去噪强度设置为1.0,因为您实际上不希望正常的img2img行为对生成的图像产生任何影响。

指示 Pix2Pix
网站。检查站。img2img选项卡完全支持检查点。无需采取额外行动。以前,生成图片需要贡献者进行扩展:不再需要它,但仍然应该有效。大多数img2img的实现都是由同一个人实现的。
要重现原始repo的结果,请使用1.0的去噪,Euler a sampler,并在configs/instruct-pix2pix.yaml中编辑配置,以说:
use_ema: true
load_ema: true
而不是:
use_ema: false

额外的网络
一个按钮,上面有一张卡片的图片。它统一了多种额外的方法,将您的世代扩展到一个用户界面中。
在大的生成按钮旁边找到它:
额外的网络提供一套卡片,每张卡片都对应一个文件,其中包含您训练或从某个地方获得的部分模型。单击卡片将模型添加到提示中,这将影响生成。
| 额外的网络 | 目录 | 文件类型 | 如何在提示中使用 |
|---|---|---|---|
| 文本反转 | embeddings |
*.pt,图像 |
嵌入的文件名 |
| LoRA | models/Lora |
*.pt,*.safetensors |
<lora:filename:multiplier> |
| 超网络 | models/hypernetworks |
*.pt,*.ckpt,*.safetensors |
<hypernet:filename:multiplier> |
文本反转
从2021年夏天开始,在Stable Diffusion使用的语言模型CLIP中微调令牌权重的方法。作者的网站。长解释:文本反转
LoRA
一种为CLIP和Unet微调权重的方法,Stable Diffusion使用的语言模型和实际图像去噪器,于2021年发布。纸。训练LoRA的一个好方法是使用kohya-ss。
对LoRA的支持内置在Web UI中,但有一个由kohya-ss原始实现的扩展。
目前,Web UI不支持Stable Diffusion 2.0+模型的LoRA网络。
通过将以下文本放入任何位置将LoRA添加到提示符中:<lora:filename:multiplier>,其中filename是磁盘上带有LoRA的文件的名称,不包括扩展名,multiplier是一个数字,通常从0到1,允许您选择LoRA对输出的影响程度。LoRA不能添加到负提示中。
将LoRA添加到提示符的文本<lora:filename:multiplier>仅用于启用LoRA,然后从提示符中删除,因此您无法像[<lora:one:1.0>|<lora:two:1.0>]使用提示编辑的技巧。具有多个不同提示的批次将仅使用第一个提示中的LoRA。
更多LoRA类型
从1.5.0版本开始,webui通过内置扩展支持其他网络类型。
请参阅[PR]中的细节
超网络
一种为CLIP和Unet微调权重的方法,Stable Diffusion 使用的语言模型和实际图像去噪器,由我们的朋友于2022年秋季在Novel AI慷慨捐赠给世界。除了为一些图层共享权重外,其工作方式与LoRA相同。乘数可用于选择超网络对输出的影响程度。
向提示符添加超网络的规则与LoRA相同:<hypernet:filename:multiplier>。
Alt-扩散
- 从huggingface下载检查站。点击向下箭头下载。
- 将文件放入
models/Stable-Diffusion
注释:
在机械上,注意力/强调机制得到了支持,但效果似乎要小得多,可能是由于Alt-Diffusion的实施方式。
不支持剪辑跳过,设置被忽略。
- It is recommended to run with
--xformers.Adding additional memory-saving flags such as--xformers --medvramdoes not work.
Stable Diffusion 2.0
- 从huggingface下载您的检查点文件。点击向下箭头下载。
-
将文件放入
models/Stable-Diffusion -
768(2.0)-(模型)
- 768(2.1)-(模型)
- 512(2.0)-(模型)
注释:
如果2.0或2.1正在生成黑色图像,请使用--no-half启用全精度,或尝试使用--xformers优化。
注:由于其新的交叉注意力模块,SD 2.0和2.1对FP16数值不稳定性(如此处所述)更敏感。
在fp16上:在webui-user.bat中启用注释:
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=your command line options
set STABLE_DIFFUSION_COMMIT_HASH="c12d960d1ee4f9134c2516862ef991ec52d3f59e"
set ATTN_PRECISION=fp16
call webui.bat
深度引导模型
深度引导模型只能在img2img选项卡中工作。更多信息。PR。
喷漆模型SD2
专为在SD 2.0 512基础上训练的inpainting设计的模型。
- 512 inpainting(2.0)-(模型+yaml)-
.safetensors
inpainting_mask_weight或油漆调理面罩强度也适用于此。
画外画
Outpainting扩展了原始图像,并绘制了创建的空白空间。
示例:
| 原版 | 画外画 | 再次外出绘画 |
|---|---|---|
 |
 |
 |
来自4chan的匿名用户的原始图像。谢谢你,匿名用户。
您可以在底部的img2img选项卡中找到该功能,在Script -> Poor man's outpainting下。
与普通图像生成不同,Outpainting似乎从大步数中获益匪张。良好的外画配方是一个很好的提示,可以匹配图片、去噪滑块和CFG刻度设置为最大值,以及使用欧拉祖先或DPM2祖先采样器的步数为50到100。
| 81步,欧拉A | 30步,欧拉A | 10步,欧拉A | 80步,欧拉A |
|---|---|---|---|
 |
 |
 |
 |
绘画
在img2img选项卡中,在图像的一部分上绘制一个遮罩,该部分将被绘制。

绘画选项:
- 在网络编辑器中自己画一个面具
- 在外部编辑器中擦除图片的一部分,并上传透明图片。任何略微透明的区域都将成为口罩的一部分。请注意,一些编辑器默认将完全透明的区域保存为黑色。
- 将模式(图片右下角)更改为“上传遮罩”,并为遮罩选择单独的黑白图像(白色=油漆)。
绘画模型
RunwayML训练了一个专门为内绘设计的额外模型。该模型接受额外的输入-没有噪音的初始图像加上掩码-并且似乎在工作中要好得多。
模型的下载和额外信息在这里:https://github.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion
要使用该模型,您必须重命名检查点,使其文件名以inpainting.ckpt结尾,例如1.5-inpainting.ckpt。
之后,只需选择检查点,就像你通常会选择任何检查点一样,你就可以走了。
屏蔽内容
屏蔽内容字段确定内容在绘制之前被放置在屏蔽区域。这并不代表最终输出,它只是看看中间发生了什么。
| 面具 | 填充物 | 原版 | 潜在噪音 | 潜伏什么都没有 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
油漆区域
Normally, inpainting resizes the image to the target resolution specified in the UI. With Inpaint area: Only maskedenabled, only the masked region is resized, and after processing it is pasted back to the original picture. This allows you to work with large pictures and render the inpainted object at a much larger resolution.
| 输入的信息 | 油漆区域:全图 | 油漆区域:仅遮盖 |
|---|---|---|
 |
 |
 |
屏蔽模式
屏蔽模式有两种选择:
- 油漆蒙版-蒙版下的区域是彩绘的
- 油漆没有遮罩-遮罩下没有变化,其他一切都被涂上了
Alpha面具
| 输入的信息 | 输出信息 |
|---|---|
 |
 |
彩色素描
img2img选项卡的基本着色工具。基于Chromium的浏览器支持滴管工具。 (这是在火狐上)
(这是在火狐上)
提示矩阵
Separate multiple prompts using the | character, and the system will produce an image for every combination of them. For example, if you use a busy city street in a modern city|illustration|cinematic lighting prompt, there are four combinations possible (first part of the prompt is always kept):
a busy city street in a modern citya busy city street in a modern city, illustrationa busy city street in a modern city, cinematic lightinga busy city street in a modern city, illustration, cinematic lighting
将按此顺序生成四张图像,所有图像都具有相同的种子,并且每个图像都有相应的提示:
另一个例子,这次有5个提示和16个变体:
您可以在底部的脚本->提示矩阵下找到该功能。
稳定的扩散高档
ℹ️注意:这不是首选的向上缩放方法,因为这会导致SD因平铺而失去对图像其余部分的注意力。它只应在VRAM绑定时使用,或与ControlNet +瓷砖模型等东西一起使用。有关首选方法,请参阅Hires. fix。
使用RealESRGAN/ESRGAN升级图像,然后浏览结果的瓷砖,使用img2img改进它们。它还有一个选项,允许您在外部程序中自己进行升级部分,只需使用img2img浏览瓷砖即可。
原创想法:https://github.com/jquesnelle/txt2imghd。这是一个独立的实施。
To use this feature, select SD upscale from the scripts dropdown selection (img2img tab).

输入图像将升级到原始宽度和高度的两倍,UI的宽度和高度滑块指定了单个瓷砖的大小。由于重叠,瓷砖的大小可能非常重要:512x512图像需要九个512x512瓷砖(由于重叠),但只需要四个640x640瓷砖。
升级的推荐参数:
- 采样方法:欧拉a
- 去噪强度:0.2,如果你喜欢冒险,可以上升到0.4
- 更大的去噪强度是有问题的,因为SD高档在瓷砖中工作,因为扩散过程无法关注整个图像。
| 原版 | RealESRGAN | 黄玉千兆像素 | SD高档 |
|---|---|---|---|
 |
 |
 |
|
 |
 |
 |
|
 |
 |
 |
无限提示长度
键入Stable Diffusion 通常接受的超过标准75个令牌,将提示大小限制从75增加到150。输入过去会进一步增加提示大小。这是通过将提示分成75个令牌,使用CLIP的变压器神经网络独立处理每个令牌,然后在输入Stable Diffusion 的下一个组件Unet之前将结果串联。
例如,包含120个令牌的提示符将分为两个块:第一个是75个令牌,第二个是45个令牌。两者都将填充到75个令牌,并用开始/结束令牌扩展到77个。通过CLIP传递这两个块后,我们将有两个形状为(1, 77, 768)张量。将这些结果串联为(1, 154, 768)张量,然后毫无问题地传递给Unet。
BREAK关键字
添加BREAK关键字(必须大写)会用填充字符填充当前块。在BREAK文本后添加更多文本将开始一个新的块。
注意/强调
在提示符中使用()增加了模型对所附单词的关注,并且[]减少它。您可以组合多个修饰符:

备忘单:
a (word)-将对word的关注度提高1.1倍a ((word))-将对word的关注度提高1.21倍(= 1.1 * 1.1)a [word]-将对word的注意力降低1.1倍a (word:1.5)-将对word的注意力增加1.5倍a (word:0.25)-将对word的注意力降低4倍(= 1 / 0.25)a \(word\)-在提示中使用字面()字符
使用()可以像这样指定权重:(text:1.4)如果未指定重量,则假定为1.1。指定重量仅适用于()不适用于[]。
如果您想在提示符中使用任何文字()[]字符,请使用反斜杠来转义它们:anime_\(character\)
2022-09-29,添加了一个新的实现,支持转义字符和数字权重。新实现的一个缺点是,旧的实现并不完美,有时会吃字符:例如,“a(((农场))),白天”,在没有逗号的情况下,就会变成“农场白天”。正确保留所有文本的新实现不会共享此行为,这意味着您保存的种子可能会产生不同的图片。目前,设置中有一个选项可以使用旧的实现。
NAI在2022年9月29日之前使用我的实现,除了他们有1.05作为乘数,并使用{}而不是()因此,转换适用于:
- their
{word}= our(word:1.05) - 他们的
{{word}}\=我们的(word:1.1025) - 他们的
[word]\=我们的(word:0.952))(0.952 = 1/1.05) - their
[[word]]= our(word:0.907)(0.907 = 1/1.05/1.05)
循环
在img2img中选择环回脚本允许您自动将输出图像作为下一个批次的输入。相当于保存输出图像并用它替换输入图像。批处理计数设置控制您获得的迭代次数。
通常,在这样做时,您会自己为下一次迭代选择许多图像之一,因此此功能的有用性可能值得怀疑,但我设法用它得到了一些非常好的输出,否则我无法获得。
示例:(樱桃采摘结果)

来自4chan的匿名用户的原始图像。谢谢你,匿名用户。
X/Y/Z情节
创建具有不同参数的多个图像网格。X和Y用作行和列,而Z网格用作批处理维度。

使用X类型、Y类型和Z类型字段选择应该由行、列和批处理共享的参数,并将这些参数用逗号分隔输入X/Y/Z值字段。对于整数、浮点数和范围,支持。示例:
- 简单范围:
1-5\= 1,2,3,4,5
- 括号中增量的范围:
1-5 (+2)\= 1,3,510-5 (-3)\= 10,71-3 (+0.5)\= 1,1.5,2,2.5,3
- 计数在方括号内的范围:
1-10 [5]\= 1,3,5,7,100.0-1.0 [6]\= 0.0,0.2,0.4,0.6,0.8,1.0
提示S/R
提示S/R是X/Y图更难理解的操作模式之一。S/R代表搜索/替换,这就是它的作用-您输入单词或短语列表,它从列表中获取第一个并将其视为关键字,并将该关键字的所有实例替换为列表中的其他条目。
例如,提示a man holding an apple, 8k clean,提示S/Ran apple, a watermelon, a gun,你会得到三个提示:
a man holding an apple, 8k cleana man holding a watermelon, 8k cleana man holding a gun, 8k clean
该列表使用与CSV文件中一行相同的语法,因此,如果您想在条目中包含逗号,您必须将文本放在引号中,并确保引号和分隔逗号之间没有空格:
darkness, light, green, heat- 4个项目 -darkness,light,green,heatdarkness, "light, green", heat- 错误 - 4个项目 -darkness``"light,green"``heatdarkness,"light, green",heat- 右 - 3个项目 -darkness,light, green,heat
来自文件或文本框的提示
使用此脚本可以创建按顺序执行的作业列表。
输入示例:
--prompt "photo of sunset"
--prompt "photo of sunset" --negative_prompt "orange, pink, red, sea, water, lake" --width 1024 --height 768 --sampler_name "DPM++ 2M Karras" --steps 10 --batch_size 2 --cfg_scale 3 --seed 9
--prompt "photo of winter mountains" --steps 7 --sampler_name "DDIM"
--prompt "photo of winter mountains" --width 1024
示例输出:

支持以下参数:
"sd_model", "outpath_samples", "outpath_grids", "prompt_for_display", "prompt", "negative_prompt", "styles", "seed", "subseed_strength", "subseed",
"seed_resize_from_h", "seed_resize_from_w", "sampler_index", "sampler_name", "batch_size", "n_iter", "steps", "cfg_scale", "width", "height",
"restore_faces", "tiling", "do_not_save_samples", "do_not_save_grid"
调整大小
在img2img模式下调整输入图像大小有三个选项:
- 只需调整大小-只需将源图像调整为目标分辨率,即可导致宽高比不正确
- 裁剪和调整大小-调整源图像的大小,保持宽高比,以便它占据整个目标分辨率,以及伸出的裁剪部分
- 调整大小和填充-调整源图像的大小,保持宽高比,使其完全符合目标分辨率,并按源图像中的行/列填充空格
示例: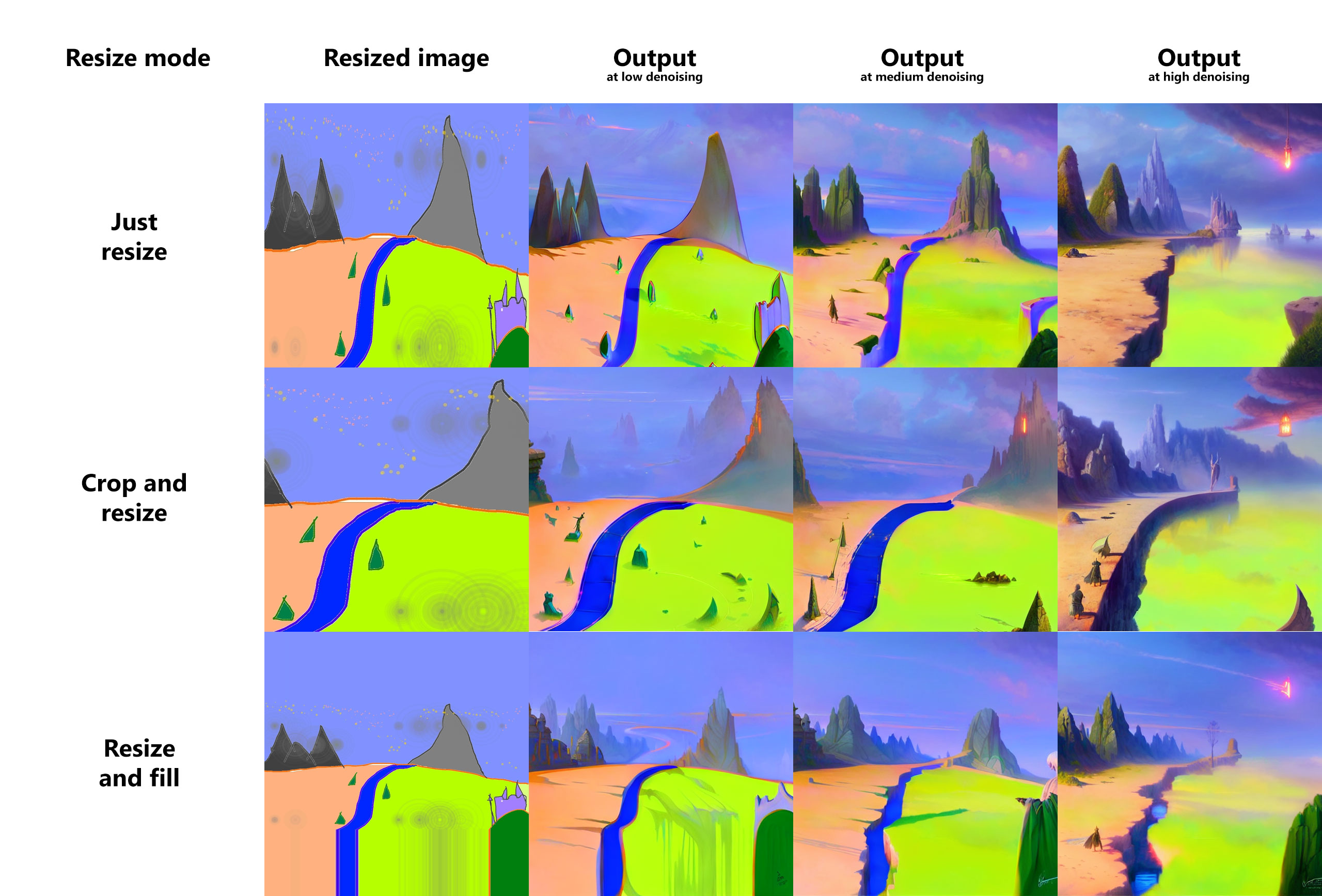
采样方法的选择
从txt2img的多种采样方法中挑选出来:

种子大小调整
此功能允许您以不同的分辨率从已知种子生成图像。通常,当您更改分辨率时,图像会完全改变,即使您保留了包括种子在内的所有其他参数。通过调整种子大小,您可以指定原始图像的分辨率,模型很可能会产生与之非常相似的东西,即使分辨率不同。在下面的示例中,最左边的图片是512x512,其他图片的参数完全相同,但垂直分辨率更大。
| 信息 | 图像 |
|---|---|
| 未启用种子大小调整 |  |
| 种子从512x512调整大小 |  |
祖先采样器在这方面比其他采样器差一点。
您可以通过单击种子附近的“额外”复选框来找到此功能。
变化
变体强度滑块和变体种子字段允许您指定现有图片应更改多少,使其看起来像不同的图片。在最大强度下,您将获得带有变异种子的图片,至少-带有原始种子的图片(使用祖先采样器时除外)。

您可以通过单击种子附近的“额外”复选框来找到此功能。
风格
按“将提示符另存为样式”按钮,将当前提示符写入styles.csv,该文件包含样式集合。提示符右侧的dropbox将允许您从之前保存的样式中选择任何样式,并自动将其附加到您的输入中。要删除样式,请从styles.csv中手动删除它,然后重新启动程序。
如果您在样式中使用特殊字符串{prompt},它将将当前提示符中的任何内容替换到该位置,而不是将样式附加到您的提示符中。
负面提示
允许您使用模型在生成图片时应避免的其他提示。这通过在采样过程中使用无条件条件条件的负提示而不是空字符串来工作。
高级解释:负面提示
| 原版 | 负:紫色 | 负:触手 |
|---|---|---|
 |
 |
 |
CLIP审讯者
最初作者:https://github.com/pharmapsychotic/clip-interrogator
CLIP interrogator允许您从图像中检索提示。提示符不允许您重现这个确切的图像(有时它甚至不会关闭),但它可能是一个好的开始。
第一次运行CLIP interrogator时,它将下载几千兆字节的模型。
CLIP interrogator分为两部分:第一部分是BLIP模型,从图片中创建文本描述。其他是一个CLIP模型,将从列表中选择与图片相关的几行。默认情况下,只有一个列表-艺术家列表(来自artists.csv)。您可以通过执行以下操作来添加更多列表:
- 在与webui相同的位置创建
interrogate目录 - 将文本文件放入其中,每行都有相关描述
例如,要使用哪些文本文件,请参阅https://github.com/pharmapsychotic/clip-interrogator/tree/main/clip_interrogator/data。事实上,你可以从那里获取文件并使用它们-只需跳过artists.txt,因为你已经在artists.csv中有一个艺术家列表(或者也使用它,谁会阻止你)。每个文件在最终描述中添加一行文本。如果您在文件名中添加“.top3.”,例如,flavors.top3.txt,则此文件中最相关的三行将添加到提示符中(其他数字也有效)。
有与此功能相关的设置:
Interrogate: keep models in VRAM-使用后,不要从内存中卸载Interrogate模型。对于拥有大量VRAM的用户。Interrogate: use artists from artists.csv-在审讯时添加来自artists.csv的艺术家。当您在interrogate目录中有艺术家列表时,禁用会很有用Interrogate: num_beams for BLIP-影响BLIP模型详细描述的参数(生成提示的第一部分)Interrogate: minimum description length- BLIP模型文本的最小长度Interrogate: maximum descripton length- BLIP模型文本的最大长度Interrogate: maximum number of lines in text file- 审讯者只会考虑文件中的这许多第一行。设置为0,默认值为1500,大约是4GB显卡所能处理的量。
及时编辑

提示编辑允许您开始采样一张图片,但在中间切换到其他图片。这个的基本语法是:
[from:to:when]
哪里和to是任意文本,when是一个数字,定义了应该在采样周期中进行切换的晚点。越晚,模型绘制文本代替文本的功率就越小。如果数字介于0和1之间,则为切换后步骤数的一小部分。如果是大于零的整数,那只是之后进行切换的步骤。
将一个提示编辑嵌套在另一个提示编辑中确实有效。
此外:
[to:when]-在固定数量的步骤后添加到提示中(when)[from::when]-在固定步骤数后从提示符中删除(when)
示例:a [fantasy:cyberpunk:16] landscape
- 一开始,模型将绘制
a fantasy landscape。 - 第16步后,它将切换到绘制
a cyberpunk landscape,继续从它停止幻想的地方。
Here's a more complex example with multiple edits: fantasy landscape with a [mountain:lake:0.25] and [an oak:a christmas tree:0.75][ in foreground::0.6][ in background:0.25] [shoddy:masterful:0.5] (sampler has 100 steps)
- 在开始时,
fantasy landscape with a mountain and an oak in foreground shoddy - 步骤25之后,
fantasy landscape with a lake and an oak in foreground in background shoddy - 步骤50之后,
fantasy landscape with a lake and an oak in foreground in background masterful - 步骤60之后,
fantasy landscape with a lake and an oak in background masterful - 步骤75之后,
fantasy landscape with a lake and a christmas tree in background masterful
顶部的图片是用提示制作的:
Official portrait of a smiling world war ii general, [male:female:0.99], cheerful, happy, detailed face, 20th century, highly detailed, cinematic lighting, digital art painting by Greg Rutkowski
数字0.99被您在图像上的列标签中看到的任何内容所取代。
图片的最后一列是[男性:女性:0.0],这本质上意味着你要求模特从一开始就画一个女性,而不是从男性将军开始,这就是为什么它看起来与其他人如此不同。
注意:此语法不适用于额外的网络,如LoRA。有关详细信息,请参阅此讨论帖子。有关类似功能,请参阅sd-webui-loractl扩展。
交替单词
用于交换其他每一步的便捷语法。
[cow|horse] in a field
在第1步,提示是“田野里的牛”。第2步是“田野里的马”。第3步是“田野里的牛”等等。

请参阅下面的更高级示例。在第8步,链条从“人”向后循环到“牛”。
[cow|cow|horse|man|siberian tiger|ox|man] in a field
提示编辑首先由Doggettx在这个reddit帖子中实现。
注意:此语法不适用于额外的网络,如LoRA。有关详细信息,请参阅此讨论帖子。有关类似功能,请参阅sd-webui-loractl扩展。
雇佣。修复
一个方便的选项,可以以较低的分辨率部分渲染图像,将其升级,然后以高分辨率添加细节。换句话说,这相当于在txt2img中生成图像,通过您选择的方法对其进行升级,并在img2img中对现在升级的图像进行第二次传递,以进一步完善升级并创建最终结果。
默认情况下,基于SD1/2的模型以非常高的分辨率创建可怕的图像,因为这些模型仅以512px或768px进行训练。这种方法通过在较大版本的去噪过程中利用小图片的构图来避免这个问题。通过选中txt2img页面上的“Hires. fix”复选框来启用。
| 没有 | 与 |
|---|---|
 |
 |
 |
 |
小图片以您使用宽度/高度滑块设置的任何分辨率呈现。大图片的尺寸由三个滑块控制:“缩放”乘数(雇用升级)、“调整宽度”和/或“调整高度”(雇用调整大小)。
- 如果“调整宽度大小”和“调整高度到”为0,则使用“缩放方式”。
- 如果“调整宽度大小为”为0,则“调整大小高度为”按宽度和高度计算。
- 如果“调整高度到”为0,则“调整宽度到”从宽度和高度计算。
- 如果“调整宽度大小”和“调整高度”都非零,则图像会升级为至少这些尺寸,并且某些部分会被裁剪。
在旧版本的webui中,最终的宽度和高度是手动输入的(上面列出的最后一个选项)。在新版本中,默认是使用“Scale by”因子,这是默认和首选。
升级商
下拉菜单允许您选择用于调整图像大小的升级器类型。除了在额外选项卡上提供的所有升级器外,还有一个升级潜在空间图像的选项,这是内部Stable Diffusion 的工作原理-对于3x512x512 RGB图像,其潜在空间表示将是4x64x64。要查看每个潜在空间提升器的作用,您可以将去噪强度设置为0,将雇用步骤设置为1-您将获得一个非常好的近似值,即在升级图像上Stable Diffusion 将使用什么。
以下是不同潜在高档模式的示例。
| 原版 |
|---|
 |
| 潜在,潜在(抗锯齿) | 潜伏(bicubic),潜伏(bicubic,抗锯齿) | 潜在(最近) |
|---|---|---|
 |
 |
 |
反锯齿变体是由贡献者PRd的,似乎与非反锯齿相同。
可组合扩散
一种允许组合多个提示的方法。使用大写和组合提示
a cat AND a dog
Supports weights for prompts: a cat :1.2 AND a dog AND a penguin :2.2 The default weight value is 1. It can be quite useful for combining multiple embeddings to your result: creature_embedding in the woods:0.7 AND arcane_embedding:0.5 AND glitch_embedding:0.2
使用低于0.1的值几乎不会产生影响。a cat AND a dog:0.03将产生基本相同的输出a cat
通过继续在您的总数中附加更多提示,这对于生成微调的递归变化非常方便。creature_embedding on log AND frog:0.13 AND yellow eyes:0.08
中断
按中断按钮停止当前处理。
4GB显卡支持
低VRAM的GPU的优化。这应该可以在具有4GB内存的显卡上生成512x512图像。
--lowvram是basujindal对优化想法的重新实现。模型被分离成模块,只有一个模块保存在GPU内存中;当另一个模块需要运行时,前一个模块将从GPU内存中删除。这种优化的性质使处理运行速度变慢——与我的RTX 3090的正常运行相比,大约慢了10倍。
--medvram是另一种优化,应该通过不在同一批次中处理有条件和无条件的去噪来显著减少VRAM的使用。
这种优化的实现不需要对原始Stable Diffusion 代码进行任何修改。
面部修复
允许您使用GFPGAN或CodeFormer改进图片中的面孔。每个选项卡中都有一个复选框来使用面部恢复,还有一个单独的选项卡,仅允许您在任何图片上使用面部恢复,滑块可以控制效果的可见程度。您可以在设置中在两种方法之间进行选择。
| 原版 | GFPGAN | 代码Former |
|---|---|---|
 |
 |
 |
检查站合并
由匿名捐赠者慷慨捐赠的指南。

包含其他信息的完整指南在这里:https://imgur.com/a/VjFi5uM
节约
单击输出部分下的保存按钮,生成的图像将保存到设置中指定的目录;生成参数将附加到同一目录中的csv文件中。
正在载入
Gradio的加载图形对神经网络的处理速度有非常负面的影响。当带有gradio的选项卡不活跃时,我的RTX 3090使图像速度提高了约10%。默认情况下,用户界面现在隐藏加载进度动画,并将其替换为静态“加载...”文本,从而实现相同的效果。使用--no-progressbar-hiding命令行选项来恢复此并显示加载动画。
缓存模型

如果您想在模型之间更快地交换,请在设置中增加计数器。Webui将在内存中保留您交换的模型。
确保您根据剩余的可用内存设置了适当的数字。
及时验证
Stable Diffusion 对输入文本长度有限制。如果您的提示太长,您将在文本输出字段中收到一条警告,显示文本的哪些部分被模型截断和忽略。
PNG信息
将有关生成参数的信息作为文本块添加到PNG中。您可以稍后使用任何支持查看PNG块信息的软件查看此信息,例如:https://www.nayuki.io/page/png-file-chunk-inspector
设置
带有设置的选项卡允许您使用UI编辑以前是命令行的一半以上的参数。设置保存到config.js。保留为命令行选项的设置是启动时所需的设置。
文件名格式
设置选项卡中Images filename pattern字段允许自定义生成的txt2img和img2img图像文件名。此模式定义了您想要包含在文件名中的生成参数及其顺序。支持的标签是:
[seed], [steps], [cfg], [width], [height], [styles], [sampler], [model_hash], [model_name], [date], [datetime], [job_timestamp], [prompt_hash], [prompt], [prompt_no_styles], [prompt_spaces], [prompt_words], [batch_number], [generation_number], [hasprompt], [clip_skip], [denoising]
不过,这个列表将随着新的添加而不断发展。您可以通过将鼠标悬停在UI中的“图像文件名模式”标签上来获得支持标签的最新列表。
模式示例:[seed]-[steps]-[cfg]-[sampler]-[prompt_spaces]
关于“prompt”标签的注意事项:[prompt]将在提示字之间添加下划线,而[prompt_spaces]将保持提示符完好无损(更容易再次复制/粘贴到UI中)。[prompt_words]是提示符的简化和清理版本,已用于生成子目录名称,仅包含提示符的单词(无标点符号)。
如果您将此字段留空,将应用默认模式([seed]-[prompt_spaces])。
请注意,标签实际上是在图案内替换的。这意味着您还可以将非标签单词添加到此模式中,以使文件名更加明确。例如:s=[seed],p=[prompt_spaces]
用户脚本
如果程序使用--allow-code选项启动,则在页面底部的脚本->自定义代码下,有一个额外的脚本代码文本输入字段。它允许您输入将完成图像工作的python代码。
在代码中,使用p变量从Web UI访问参数,并使用display(images, seed, info)功能为Web UI提供输出。脚本中的所有全局变量也可以访问。
一个简单的脚本,只需处理图像并正常输出:
import modules.processing
processed = modules.processing.process_images(p)
print("Seed was: " + str(processed.seed))
display(processed.images, processed.seed, processed.info)
用户界面配置
您可以在ui-config.json中更改UI元素的参数,它在程序首次启动时自动创建。一些选项:
- 无线电组:默认选择
- 滑块:默认值,最小值,最大值,步进
- 复选框:选中状态
- 文本和数字输入:默认值
当设置为UI配置条目时,通常扩展隐藏部分的复选框最初不会这样做。
埃斯甘
可以在Extras选项卡以及SD高档中使用ESRGAN模型。纸在这里。
要使用ESRGAN模型,请将它们放入与webui.py位于同一位置的ESRGAN目录中。如果文件具有.pth扩展名,则将作为模型加载。从模型数据库中获取模型。
并非数据库中的所有模型都受支持。所有2x型号很可能都不受支持。
img2img替代测试
使用欧拉扩散器的反向解构输入图像,以创建用于构建输入提示的噪声模式。
例如,您可以使用此图像。从脚本部分中选择img2img替代测试。

调整重建过程的设置:
- 对场景进行简短描述:“一个棕色头发的微笑女人。”描述您想要更改的功能会有所帮助。将此设置为开始提示,并在脚本设置中设置为“原始输入提示”。
- 您必须使用欧拉采样方法,因为此脚本是建立在它之上的。
- 采样步骤:50-60。这非常匹配脚本中的解码步骤值,否则你会过得很糟糕。使用50进行此演示。
- CFG等级:2或更低。对于这个演示,请使用1.8。(提示,您可以编辑ui-config.json将“img2img/CFG Scale/step”更改为.1而不是.5。
- 去噪强度-这确实很重要,与旧文件所说的相反。将其设置为1。
- 宽度/高度-使用输入图像的宽度/高度。
- 种子......你可以忽略这个。反向欧拉现在正在为图像产生噪声。
- 解码cfg比例-低于1的地方是最佳点。对于演示,使用1。
- 解码步骤-如上所述,这应该与您的采样步骤相匹配。演示为50,考虑增加到60,以获得更详细的图像。
一旦上述所有内容都拨入,您应该能够点击“生成”并返回一个与原始结果非常接近的结果。
在验证脚本正在以良好的准确性重新生成源照片后,您可以尝试更改提示的细节。原件的更大变化可能会导致图像的构图与来源完全不同。
使用上述设置和下面的提示的示例输出(图中未显示红头发/小马)

一个蓝头发的微笑女人。工作。一个棕色头发的皱着眉头的女人。工作。一个皱着眉头的红头发的女人。工作。一个皱着眉头的红头发的女人骑着马。似乎完全取代了那个女人,现在我们有了一匹姜小马。
用户.css
在webui.py附近创建一个名为user.css的文件,并将自定义CSS代码放入其中。例如,这使画廊更高:
#txt2img_gallery, #img2img_gallery{
min-height: 768px;
}
A useful tip is you can append /?__theme=dark to your webui url to enable a built in dark theme
例如(http://127.0.0.1:7860/?__theme=dark)
Alternatively, you can add the --theme=dark to the set COMMANDLINE_ARGS= in webui-user.bat
例如set COMMANDLINE_ARGS=--theme=dark

通知.mp3
如果webui的根文件夹中存在名为notification.mp3的音频文件,它将在生成过程完成时播放。
作为灵感的来源:
- https://pixabay.com/sound-effects/search/ding/?持续时间=0-30
- https://pixabay.com/sound-effects/search/notification/?持续时间=0-30
调整
剪辑跳过
这是设置中的滑块,它控制了CLIP网络对提示的处理应该多早停止。
更详细的解释:
CLIP是一个非常先进的神经网络,可将您的提示文本转换为数字表示。神经网络与这种数字表示配合得很好,这就是为什么SD的开发人员选择CLIP作为Stable Diffusion 生成图像方法的3个模型之一。由于CLIP是一个神经网络,这意味着它有很多层。您的提示符以简单的方式数字化,然后通过图层输入。在第一层之后,你得到提示符的数值表示,你把它输入第二层,你把结果输入第三层,等等,直到你到达最后一层,这是用于Stable Diffusion 的CLIP的输出。这是1的滑块值。但你可以早点停下来,并使用倒数最后一层的输出-即滑块值为2。你越早停止,在提示符上工作的神经网络层就越少。
一些模型是经过这种调整训练的,因此设置此值有助于在这些模型上产生更好的结果。
